
Fetch Top News Stories from Times of India
In this tutorial we are going to learn how Web-Scraping using Python to scrap required data from a website and print on our console.
We are going to use python, and its library beautiful soup.
It is very useful in the times of data science to pull data from different websites for analysis purposes
We are going to fetch top news from Times of India
You can also use to fetch data from weather or sports website or even an E-Commerce website to keep tab on your favorite item there.
We are going to use a very popular python library for this task, BeautifulSoup
What is beautiful Soup?
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree.
You should be familiar with the following (but not necessary)
- Basic python programming & Syntax
- HTML DOM elements
- Python 3 installed on your system
Let’s get started
web-Scraping using Python to scrap required data
We are going to install two libaries first: request & beautifulSoup
$ pip install requests
$ pip install beautifulsoup4
Now that we have all our libraries we will import it..
from bs4 import BeautifulSoup
import requestsWe are going to target Times Of India to fetch the Top News Stories
Right click and choose inspect element to view the HTML elements
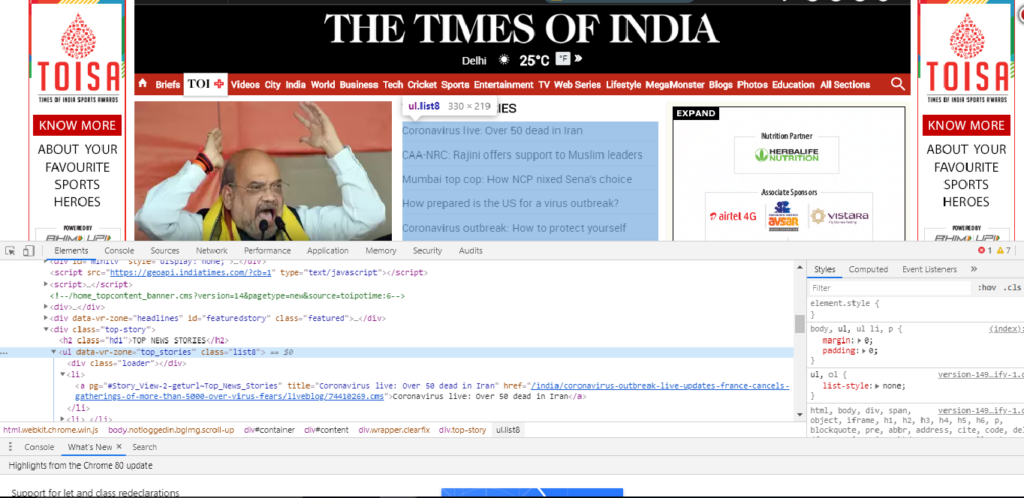
URL = "https://timesofindia.indiatimes.com/"
req = requests.get(URL)
print(req.status_code) # To Check if page existsGo to your terminal of your editor or Command Line terminal and type
>python news.py (Name of your python file)
It should print 200 on the console. It means that the page has been found and we can proceed
soup = BeautifulSoup(req.content, 'html.parser')
print(soup.prettify()) #Get content of the website in HTML structured formatThis will render the whole Times of India website and print in HTML format
Now that we have the whole HTML rendered, we can now target only the data that we need, in our case we are going to render the Top News Stories. Here’s how we can do.
tb = soup.find('div', class_='top-story')
print("Top News Story: Times Of India")
for link in tb.find_all('li'):
name = link.find('a')
print("Times: "+name.get_text('title'))On the above code we are using the find method of BeautifulSoup and targeting div elements of our class i.e ‘top-story’
We are then using a loop to find li elements and find the title within it.
Now again use command line
>python news.py
You should get this as output

This way we can parse data from any website and use it for some other python related tasks such as collecting huge amount of data or for Data analytics purposes
We can also extend this task and use Python file-system to store our data into a txt file or also store this data into a database or simply render this data to your own website
A word of Caution: Some websites do not allow there websites to be scraped and it would be advisable to check whether we can do so.
Putting all the codes together
import requests
from bs4 import BeautifulSoup
URL = "https://timesofindia.indiatimes.com/"
req = requests.get(URL)
print(req.status_code) # To Check if page exists
print(req.content) #Get content of the website
soup = BeautifulSoup(req.content, 'html.parser')
print(soup.prettify()) #Get content of the website in HTML structured format
tb1 = soup.find('h2', class_='hd1')
print(tb1) #To fetch <h2 class="hd1">TOP NEWS STORIES</h2>
tb2 = soup.find('div', class_='top-story')
print("Top News Story: Times Of India")
for link in tb2.find_all('li'):
name = link.find('a')
print("Times: "+name.get_text('title'))Thanks for reading!!! Please comment below for more blogs like this.




